
The basic structure of any neural net machine learning process consists of a model, an “objective function”, and a way of taking said function’s gradient. An objective function is a way of measuring the performance of a model. Thusly, it is also sometimes called a measure.
Measures are often constructed using large sets of data that are labelled with the answers that the model should be giving. One example of a measure is the mean squared error, given by:
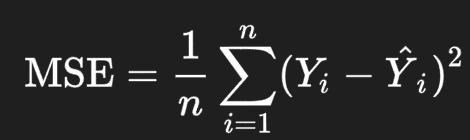
Where Y and Y^ are the value returned by the net and the value expected by the dataset, respectively for each of its elements. Other measures for neural nets include accuracy, and weighted accuracy.
In order to choose which of these would be most purposefully used with any given dataset, it is important to consider what kind of values are stored in it, and in what proportions they are stored.
Mean squared error is pretty good, generally speaking, when it comes to numerical data, but it is oftentimes better to use a simpler measure (one of the other two mentioned above) when possible, to make the model simpler to understand and build; less moving parts means something easier to optimize.
When (and only when) the labels of the dataset are from a smaller set of possible values (ex. {0, 1}) we can use some kind of accuracy as a measure. When labels are numerical and from a larger range of values, accuracy fails to capture the full picture; a 4 is definitely further from a 7 than a 6 is, but if you only look using accuracy, they are the same.
It is important to look at the balance of the dataset when deciding what kind of accuracy we want to use. This is because, in spite of the fact that we only use one measure during training (for the sake of practicality/ ease of implementation/ ease of optimization), we want the final version of the model to perform well when measured using all of the different measures; if we consider all of the measures to be reasonable, then if the model performs badly on even one of them we can say reasonably that the model is bad.
For this reason, we only use unweighted accuracy when the dataset is balanced (meaning that there are as many 1s as 0s). The basic idea behind this is that, if the dataset is unbalanced, say as an extreme example 10% 0s and 90% 1s, the model could converge to being very accurate (100%) when given 1s and very inaccurate (50%) when given 0s, and still be called good by unweighted accuracy; weighted accuracy would call this sort of model very bad (0.5*50+0.5*100 = 75).

Leave a comment